
Taking Advantage of the Sum of Errors
September 30, 2012
Estimating project schedules is hard. It is especially difficult for larger projects, and it is not uncommon for projects in my industry, software development, to be underestimated by several multiples. Sometimes, an order of magnitude and up.
I am not going into why that might be the case: it has been widely discussed and may the subject of a future post, but suffice to say, it happens all the time, and even to experienced project managers. Here is one way to look at project estimating that helps me keep things mostly reasonable, most of the time.
Consider an interesting little script that you think might take 10 hours to write. For the purpose of this example, let’s say that our estimates are always 50% off, in one direction or the other. This might seem egregious to you, but in the software industry only being 50% off is practically omniscience.
So, we have made a 10 hour estimate with an expected error of 50%. The script will actually take either 5 hours or 15 hours to actually finish. How can we improve on this?
What if we break down the work of doing the script into 10 smaller pieces and estimate each of these individually? Even a small script will require a documentation/usage page, command-line option parsing, some sort of input processing, maybe an algorithm or two, some output, some error-checking, perhaps a non-trivial edge case it might need to handle. Don’t forget the effort of creating a Github gist for this, or creating a remote source-code repo to which you can push your hard work.
Now we have 10 items, and we try really hard to accurately estimate each one individually. By sheer coincidence, our best estimate for each of these 10 items is 1.0 hours, providing a total estimate of 10 hours for the script. And our estimation error is still exactly 50%, so each item in our estimate will actually take either 0.5 or 1.5 hours to complete. Assuming we err on either side equally, here is the estimated vs. actual for this project.
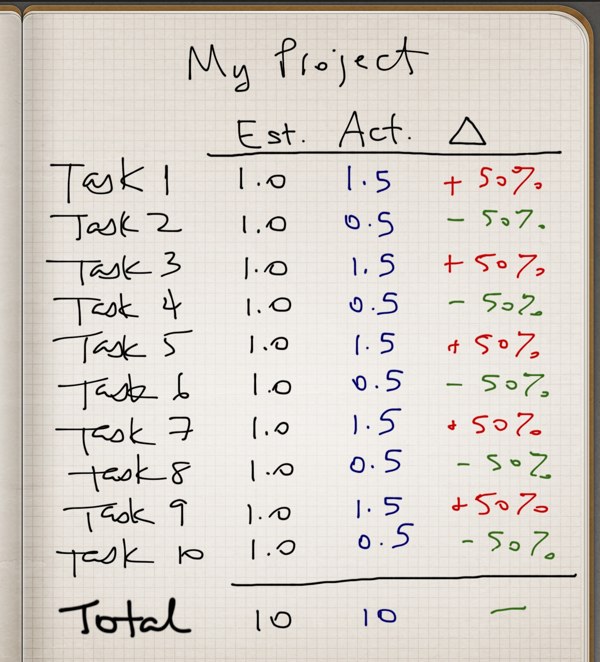
Figure 1: Sum of Errors
The individual estimation errors for each task have effectively cancelled each other out, giving us an extremely accurate overall estimate.
Sure, these numbers are contrived for the purpose of this example, but the punchline is still useful: the more chunks into which you decompose your project, the more accurate your estimate will tend to be. The sum of errors will approach 0 as the number of estimates increases, assuming a normal error distribution.
An unfortunate consequence of more accurate estimates tends to be larger estimates. But that’s a subject for another day.

I'm Gene Goykhman, software developer, entrepreneur and principal at Indigo Technologies Ltd. I work on the TimeTiger time and project tracking system and play with some tasty projects on the side. I have lots of opinions about stuff.
Have a comment? Find me on Mastodon @genegoykhman